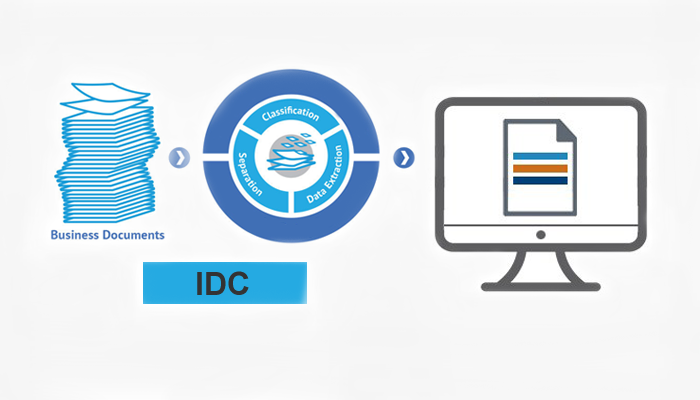
For less-structured document types, the subfield of intelligent data capture was developed. This new approach takes a content-based, rather than layout-based, approach to documents. Most modern capture solutions that utilize IDC depend on a pre-production learning phase, during which human operators provide example documents. The software then scans and analyzes all the words on every page in order to build a statistical model of word relationships and probabilities. For example, an operator may provide an example of both a mortgage document and a land usage document; the system will build a model that effectively notes the presence of terms like borrower, SSN, interest, and principal in the former document, while prioritizing words such as title, bounds, survey, easement, and so on for the latter. In actuality, this example is quite simplistic, whereas the extensive matrices that today’s systems can generate are quite nuanced and sophisticated.